今回のテーマは、C言語で日本語(全角)を扱う場合についてです。
この記事では 「char型とは」 「文字コードとは」 「全角文字の出力」 について書いています。
まずはchar型とは何か、文字コードとは何かについて基礎的なことを確認していきましょう。
【char型とは】
データ型の一つ。
データ型とは、変数の中身がどんな種類のデータなのかを表すものです。
C言語におけるchar型とは、半角1文字を扱うデータ型です。
サイズは1Byte(8bit)となります。
このサンプルでは、基本的なchar型の動作を確認することが出来ます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
#include <stdio.h> int main(void) { char data1 = 'A'; //文字形式で初期化 char data2 = 65; //10進数の数値形式で初期化 char data3 = 0x41; //16進数の数値形式で初期化 printf("%c\n", data1); printf("%c\n", data2); printf("%c\n", data3); return 0; } |
【実行結果】

このように、どの形式で初期化しても結果は同じAと言う文字が表示されています。
よって3つの変数のメモリの状態はいずれも同じ状態となっています。
具体的には3つの変数を2進数でビットの状態を表すと「0100 0001」です。
2進数、10進数、16進数の変換が苦手な方は電卓のプログラマーモードを使ってみましょう。
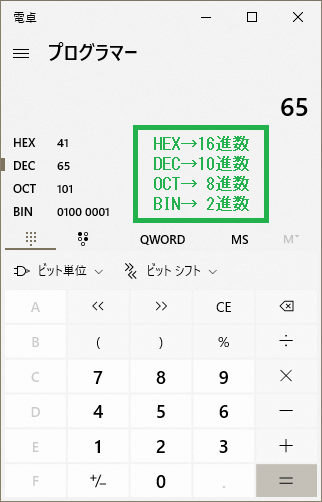
Aは65番目の文字としてコンピューターの中で登録されており、Aを16進数で表すと41番目に登録されていることが分かりました。
それってどういう風に決まっているのかというと、文字コードによって決まっています。
【文字コードとは】
文字コードとは、数値と文字の関連付けのことです。
文字コード表は文字とその数値が対になって一覧になっています。
文字コードにはいくつか種類があり、
- Shift_JIS
- UTF-8
などがあります。この2つは日本語を表現出来る文字コードです。
文字と数字がコンピューターの中で紐づいているんですね。
次は英語と日本語について見ていきましょう。
文字には2種類あって、
「a」「Z」「0」「9」のような、半角文字と
「あ」「カ」「漢」「1」のような全角文字があります。
半角文字と全角文字では1文字に必要なバイト数に違いがあります。
半角: 1Byte
全角: 数Byte
1Byteは256通りの情報しか扱えませんが、英字は文字の種類の数が少ないので1バイトで表せます。
コンピューターは英語圏で作られたので1Byteで足りていたのですね。
ただし、日本語を表すのには256通りでは足りません。
日本語はひらがな、カタカナだけでなく、漢字も扱います。
さらに漢字では同じ意味を持つ漢字でも複数の種類があったりします。
例) ①斉藤 ②斎藤 ③齋藤
このように日本語は1Byteの256種類では収まりきらない!!ということで、2Byte以上を使って1文字としています。
ちなみに2Byteは65,536通りの情報を扱えます。
先ほど文字コードに種類があるとお話ししました。
全角文字を扱った場合、
Shift-JISは2Byte
UTF-8は3Byte以上を使います。※日本語のほとんどは3Byte、第3・第4水準漢字の大半は4Byte
実際は2Byteの65536通りでは足りず、3Byte以上を必要とする文字があるという事ですね。
では、ここから本題の、日本語を変数に格納して、その文字列を出力する!をやってみたいと思います。
【sizeof演算子】
sizeof演算子を使うと、データ型や変数のサイズを測ることが出来ます。
このサンプルでは、半角の文字データと半角の文字列と全角の文字列のデータのサイズを測っています。
全角文字を表すには2Byte以上必要なので、「あ」という文字を格納するにはchar型配列を使用する必要があります。
※他の方法もあります!
このサンプルでは文字や文字列データのサイズがわかります。
データのサイズを測ることで、その全角文字データが何Byteか測ることができます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#include<stdio.h> int main(void) { char ch = 'a'; char ca1[] = "a"; char ca2[] = "あ"; printf("%d\n", sizeof(ch)); printf("%d\n", sizeof(ca1)); printf("%d\n", sizeof(ca2)); return 0; } |
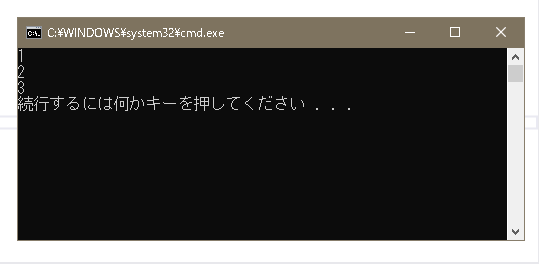
【実行結果】
変数chのような文字データはシングルクォーテーションで括ります。
変数ca1のような文字列データはダブルクォーテーションで括ります。
C言語では文字列をchar型の配列として扱います。
1文字のデータ(変数ch)のsizeof演算子を使った結果は1でした。
ca1の様な文字列データは文字の最後に「\0」という1Byteのnull文字が追加されるため、結果は2となっています。
全角の文字列データの変数ca2は結果は3となっているので、「あ」という文字列データは2Byteという事が分かりました。
※VisualStudio2017で実行しています。
ここまでで、C言語のchar型と文字コード、sizeof演算子を使った文字のサイズについて確認していきました。
char型は1バイトを扱うデータ型、全角文字を表すには2バイト以上必要という事がわかりました。
次はchar型配列を使った全角文字の文字列データを出力していきたいと思います。
ではprintf()を使って、文字列の出力をしてみましょう!
このサンプルではchar型の配列にひらがなの文字列データを格納し、出力していきます。
そして、全角文字の「こんにちは」の文字列データは、char型の配列にどのように格納されているのか見ていきましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#include<stdio.h> int main(void) { char str1[] = "こんにちは"; //文字列データ //10進数のこんにちは char str2[] = {130, 177, 130, 241, 130, 201, 130, 191, 130, 205, 0 }; //16進数のこんにちは char str3[] = {0x82, 0xb1, 0x82, 0xf1, 0x82, 0xc9, 0x82, 0xbf, 0x82, 0xcd, 0x00}; printf("%s\n", str1); printf("%s\n", str2); printf("%s\n", str3); return 0; } |
【実行結果】
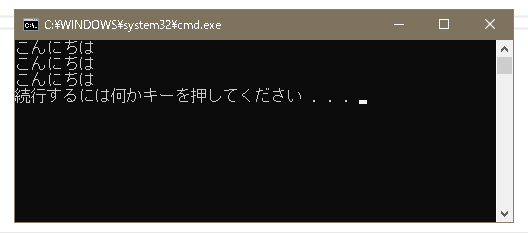
str2では、130と177の計2Byteのデータを使って「こ」を表しています。
さらに、よく見てみるとひらがなの1バイト目は130(0x82)となっていますね。
1バイト文字で使用していないコードが来たら次のコードと合わせて判断するようになっています。
当然ですが、2Byte文字を取り出す際は、配列の[0]番目だけを取り出してもうまくいかないです。
✕ printf(“%c\n”, str2[0]); //1Byte分しか取り出していない
配列の0番目と1番目に入っているデータの文字「こ」を1文字として表示するには、
〇 printf(“%c%c\n”, str2[0], str2[1]);
と、記述することで「こ」が表示されます!
ちなみにchar型の配列に、ひらがなの「あ」をシングルクォーテーションで括って代入すると、全角文字は2バイト使うので「あ」という文字データは入りきらないです。
✕ char a[] = {‘あ’}; //1Byteに2Byte入れようとしてる
【メモリダンプ】
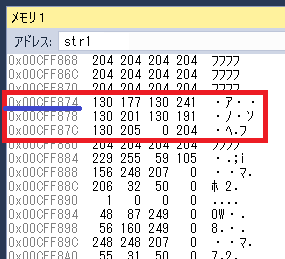
全角文字列データの10進数16進数表記がわからないよ~(._.)という方は、メモリダンプをみてみると10進数や16進数の値を見ることが出来ます!
先ほどのサンプルのstr1のアドレスを使ってUnsigned(10進数)や16進数表示でメモリの中をみてみます。
str2やstr3に代入したデータと同じという事が確認できます。
【10進数表示】 【16進数表示】
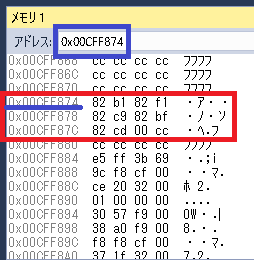
【まとめ】
今回はC言語で日本語(全角文字)の文字列の出力を行いました。
全角文字列データを表すには、どうして配列なのか、全角文字はどれくらいのデータサイズなのか
そしてどのように出力するのか確認することができました。
英語圏で開発されたC言語で日本語を扱うのは少し不便なところもありましたが、仕組みを理解することで全角文字も出力する事が出来ました!👏